Fastest way to insert the data in MS SQL - Part 1 Hibernate Batching
Introduction
Currently, my team is focused on optimizing the performance of our
web services. Our data manipulation tasks primarily rely on Hibernate for
interacting with our MS SQL Server database. Hibernate provides a convenient
and straightforward API for handling data, particularly for persisting individual
or interconnected objects (object graph).
However, when it comes to bulk operations, Hibernate's default behavior
may not be as efficient. To address this, you can enhance performance by
enabling Hibernate batching in the application.properties file.
1hibernate.jdbc.batch_size=<batch size>
You have the option to dynamically adjust the batch size by manipulating the
Session object. To illustrate, if you intend to configure a batch size of 50
for a specific session, you can achieve this goal with the following code snippet:
1entityManager
2 .unwrap(Session.class)
3 .setJdbcBatchSize(batchSize);
Once you have enabled Hibernate batching, you can start to see performance improvements in your application, especially if you are performing a large number of database operations.
Here are some additional tips for using Hibernate batching:
- A batch size that is too small will not provide much performance improvement, while a batch size that is too large can cause memory problems.
- To enable Hibernate to batch all statements, you need to set the
hibernate.order_insertsandhibernate.order_updatesproperties totrue. - If you work wit
- h Spring Boot application, you can enable batching by using prefix
spring.jpa.properties.hibernate.*.
Example
Let's try to persist list of Person objects using Hibernate. Person object is defined as following:
1@AllArgsConstructor
2@NoArgsConstructor
3@Entity
4@Table(name = PERSON_TABLE_NAME)
5@Getter
6@Setter
7public final class Person {
8 @Id
9 @Column(name = "person_id", columnDefinition = "INT")
10 private int personId;
11 @Column(name = "user_name", nullable = false, length = 30, columnDefinition = "NVARCHAR(30)")
12 private String userName;
13 @Column(name = "first_name", nullable = false, length = 10, columnDefinition = "NVARCHAR(10)")
14 private String firstName;
15 @Column(name = "last_name", nullable = false, length = 15, columnDefinition = "NVARCHAR(15)")
16 private String lastName;
17 @Column(name = "years", columnDefinition = "INT")
18 private int years;
19}
As you can tell, this is a pretty standard Hibernate entity with 2 integer fields and 3 string fields. Just remember, the personId doesn't get created on its own; you've got to give it a value.
Random data is generated using following method;
1private static Person genRandomPerson() {
2 ++personId;
3 return new Person(personId,
4 RandomStringUtils.randomAlphanumeric(30),
5 RandomStringUtils.randomAlphabetic(10),
6 RandomStringUtils.randomAlphabetic(15),
7 RandomUtils.nextInt(10, 100)
8 );
9}
We will consider 2 different ways to insert this data.
- Using
persistmethod fromEntityManager. - Using
saveAllmethod fromPersonRepository.
Those functions are defined as following:
1public void persist(List<Person> people, int batchSize) {
2 if(CollectionUtils.isEmpty(people)){
3 return;
4 }
5
6 // set manual flush mode
7 entityManager.setFlushMode(FlushModeType.COMMIT);
8 // flush and clear everything from entity manager
9 entityManager.flush();
10 entityManager.clear();
11
12 for(List<Person> chunk : Lists.partition(people, batchSize)) {
13 persistAndFlushObjects(chunk);
14 }
15 entityManager.setFlushMode(FlushModeType.AUTO);
16}
17
18private <T> void persistAndFlushObjects(Iterable<T> objects) {
19 for (T object : objects) {
20 entityManager.persist(object);
21 }
22 entityManager.flush();
23 entityManager.clear();
24}
The persist function is the one that uses the entityManager to save objects.
It's crucial to emphasize that this function should exclusively be used
for inserting new objects into the database. It accomplishes this by
partitioning the input list into multiple sublists,
each of which has a size batchSize.
Subsequently, after each sublist is persisted into the entity manager,
the flush and clear methods are invoked to both transmit the data to the database
and reset the persistence context.
In addition, we set flush mode to manual, all changes are deliberately flushed to the database before initiating the process. This approach allows for more precise control over when the data is actually transmitted to the database.
And here is the second function:
1public void saveAll(List<Person> people) {
2 personRepository.saveAllAndFlush(people);
3}
This function simply uses PersonRepository method saveAllAndFlush.
Person repository is standard JPA repository defined as following:
1@Repository
2public interface PersonRepository extends JpaRepository<Person, Integer> {}
Results
I execute these two methods in distinct scenarios:
one with the batching parameter turned on and the other with it turned off.
Additionally, I conduct the tests using varying batch sizes for each scenario,
specifically batch sizes of 10, 100, and 1,000. 100,000 Person
objects are persisted to the database.
In each test scenario, I run the test 10 times and compute the median value
from the results. Following the completion of each test,
I truncate the Person table. My measurements exclusively focus on the time
taken for the insert operations to conclude.
Here are the results:
| Method name | Median duration ms | Batch size |
|---|---|---|
| PersistBatched | 1675 | 1000 |
| PersistBatched | 2237.5 | 100 |
| PersistBatched | 4787 | 10 |
| Persist | 10767.5 | 10 |
| Persist | 10797.5 | 100 |
| Persist | 11085 | 1000 |
| SaveAllBatched | 12756.5 | 1000 |
| SaveAllBatched | 12993 | 100 |
| SaveAllBatched | 14059 | 10 |
| SaveAll | 21133 | 1000 |
| SaveAll | 21164.5 | 100 |
| SaveAll | 21908.5 | 10 |
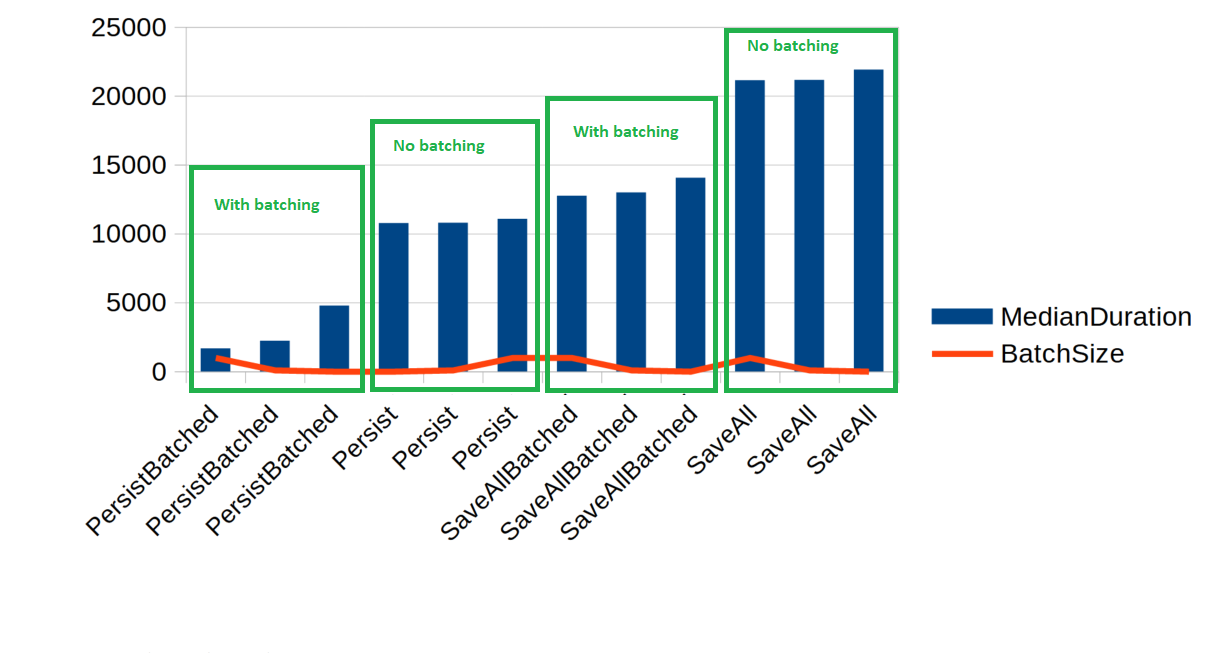
Indeed, the chart clearly demonstrates that enabling batching results in the fastest data insertion. It's also evident that larger batch sizes correspond to faster persistence. However, it's essential to exercise caution when considering further increases in batch size, as this can lead to memory usage issues.
The unexpected second-place performance is intriguing, given the conventional expectation that batched methods should outperform. To gain a deeper understanding of what's happening, we'll employ a profiler and examine the SQL operations. Specifically, I will activate the profiler and insert at least 3 persons with a batch size of 3 for each method to investigate this further.
Persist - batching off
1exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'FFZQXDJQUW',N'CtJFyhZDmQObnmk',N'aTUyaBJdYD1sZJMshs8sRPIVLg4rKs',39,1
2exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'BjFjOuBuJH',N'yYdQwHJXsJfIqlM',N'qIaa3HcHb2uJqJe6uey8j6Ia7wQtO4',69,2
3exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'ssXhcZASed',N'AQGJYshznwUtSVs',N'YysiILjKLdzoneD0jgh2FL37QIiRpI',47,3
SaveAll - batching off
1
2exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',7
3exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',8
4exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',9
5exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'jetpalOgkj',N'MnSwdgaGgvSSRkr',N'KBEOdFrt8b2D4EXP1waY5YtBWIvNKK',48,7
6exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4int',N'ZxhPKruIKE',N'wsupRsfIfmCypry',N'Y8mRpSzqd0RzZhJ9zLT07XelNtM8L0',24,8
7exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'HKFDsDrUON',N'wubsXMqCnSWoIIp',N'Q2POp78YTUeFr1W2G3XwB7H9EkgpKH',42,9
SaveAll - batching on
1
2exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',4
3exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',5
4exec sp_executesql N'select p1_0.person_id,p1_0.first_name,p1_0.last_name,p1_0.user_name,p1_0.years from person p1_0 where p1_0.person_id= @P0 ',N'@P0 int',6
5exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'UKXIAjQpKW',N'JIbTaOjCPMyyWnl',N'bVISG7MpaJriTL1tjwYtE5pPKtSEKI',96,4
6declare @p1 int
7set @p1=1
8exec sp_prepexec @p1 output,N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'NiZUusgbTI',N'QOtzVxVYnDVTiml',N'WEjQzTHKqwPco0TcYA7tiDLpC0neWk',95,5
9select @p1
10exec sp_execute 1,N'NnKjQPqXam',N'QCgmsEFKwWdNRBV',N'vu3NXw6KRZ3fZ3wc3Sx3Wk2dYlGFmg',71,6
Persist - batching off
1
2exec sp_executesql N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'HgTNGeptBc',N'YvYmAUhiAfnQRTx',N'E2oyRByYVlaqWs6xamqmHtEl2TUp2J',43,10
3declare @p1 int
4set @p1=2
5exec sp_prepexec @p1 output,N'@P0 nvarchar(4000),@P1 nvarchar(4000),@P2 nvarchar(4000),@P3 int,@P4 int',N'insert into person (first_name,last_name,user_name,years,person_id) values ( @P0 , @P1 , @P2 , @P3 , @P4 )',N'WHlTNmwAhz',N'MCUejiZXmAaQayn',N'yJNPUG9ejuOBiFyz3koKVSqYtvA527',73,11
6select @p1
7exec sp_execute 2,N'gDiAwqlEtU',N'oJllYKcGNkXpxie',N'AyKsziLzNYdFj4QHSoPcVXwEiCuOKF',21,12
The observed behavior where select statements are executed for each insert
statement when the saveAll method is invoked is due to a specific reason.
When we use the save method with supplied identity, Hibernate cannot be
certain whether the record already exists in the database. Consequently,
it needs to verify this by executing a select statement for each entity,
leading to the additional select operations during the insertion process.
Here is the code snippet that defines the save method within the Hibernate source code:
1@Transactional
2@Override
3public <S extends T> S save(S entity) {
4
5 Assert.notNull(entity, "Entity must not be null");
6
7 if (entityInformation.isNew(entity)) {
8 em.persist(entity);
9 return entity;
10 } else {
11 return em.merge(entity);
12 }
13}
Conclusion
The results clearly indicate that enabling the batching parameter significantly enhances insert performance when working with Hibernate. Therefore, considering the activation of batching in your project can yield substantial performance improvements.
The second key takeaway is the importance of exercising caution and continuously monitoring performance when working with Hibernate. It's possible that Hibernate may not operate optimally out of the box, but with some straightforward code adjustments, you can achieve dramatic performance enhancements. This highlights how important it is to carefully measure performance and examine it closely to get the best results.